Gadi Briskman
Product Manager at Modcon Systems Ltd
The essence of profit maximization at refineries is keeping the plant at an optimal setpoint at all times. This task has been the focus of the process optimization industry since the late 1970s. Its solution, as it historically evolved, has two parts to it. The first is to find the optimal setpoint and the second is to track it, returning the controlled variables of the process (CVs) to the precalculated setpoint, once they deviate from it as a result of disturbances.
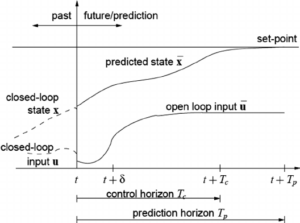
Figure 1
The family of algorithms dedicated to finding the optimal static setpoint was called RTO (Real Time Optimization). The solutions dedicated to tracking that static setpoint were based on the Model Predictive Control (MPC) approach. The reason for this historic split is computational. While the RTO involved non-linear equations, its practical implementation wasn’t feasible until the late 1980s. MPC algorithms, working on linearized plant models started to be adopted in the refining industry about ten years prior to that. Please see the illustration of the RTO/MPC approach in Figure 1.
Splitting process optimization into finding setpoints and tracking them has its limitations. Setpoint trajectories found by RTO may not be feasible for tracking under the constraints of the MPC. Maintaining two separate plant models, one for RTO and one for MPC, creates an additional workload on the operating personnel. This adds to the limitations of RTO and MPC on their own to reliably model the process. Still, working in the paradigm of MPC and RTO remains the mainstream approach to optimization in the processing industry. At the same time, we see the trend in academia and industry to seek integrated optimization solutions within the limitations of what is computationally feasible for calculation in real time.
Our approach addresses the shortcoming of the traditional approach to plant economic optimization, by leveraging the tools of Machine Learning, tightly integrated with on-line analyzers. The cornerstone of the solution is a trained advanced predictive model of the plant. This model is implemented in an ML algorithm, trained on the plant’s historic data. The predictive model takes as an input the values of the manipulated variables (MV’s), and the measurable disturbances (DV’s) and produces the corresponding values of the controlled variables (CV’s) as an output. The predictive model allows searching for the MV’s, corresponding to the optimal setpoint, that minimizes the economic cost function of the plant for the current process parameters, represented by the DV’s. This search is done by an optimization algorithm, executed repeatedly at a predetermined frequency.
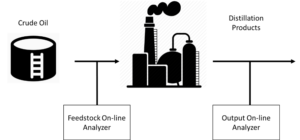
Figure 2
The quality of the described optimization results depends on two key factors. The first is the quality of the data, used for the predictive model training. The second is precise real-time identification of the feedstock parameters, serving as a part of the inputs to the predictive model. Positioning online analyzers at the input and at the output of the plant allows for addressing both factors. Please see Figure 2 for the illustration of this architecture.
During predictive model training, precise measurements of inputs and outputs of the plant done by online analyzers enable the high-fidelity ML predictive model creation. During the optimization algorithm execution, the detection of feedstock changes using online analyzers serves as a better alternative to inferring the changes in feedstock from the changes in the output. In comparison to inference models, online analyzers allow faster detection of changes and better quality of measurements.
References:
Krishnamoorthy, Dinesh; Foss, Bjarne Anton; Skogestad, Sigurd. (2018) Steady-State Real-time Optimization using Transient Measurements. Computers and Chemical Engineering. vol. 115.
Kumar, A.S., & Ahmad, Z. (2012). MODEL PREDICTIVE CONTROL (MPC) AND ITS CURRENT ISSUES IN CHEMICAL ENGINEERING. Chemical Engineering Communications, 199, 472 – 511.
